Evolution's Extinction Engine
Part 3 – 4-Dimensional Genome


Welcome back to our Literal Genesis series, where we aim to hold firmly to scripture and loosely to theories. Again, why do we do that? Because scripture never changes. That's our anchor, that's our rock. That's our solid point for our worldview as Christians. And the theories of man, theories of us flawed humans, well, they change all the time. And as we get new evidence they have to change and morph. And so we always want to hold firmly to scripture, particularly when we're talking about this theory of evolution, this idea that rocks could somehow turn into rocket scientists over eons of time. This is a theory that we want to investigate and ask of it these critical questions, and then we want to hold very loosely, because in my estimation, scripture does not support it at all.
In the previous sessions, if you remember, we talked about this idea of DNA being like a manual. Well, it's a set of manuals, a set of manuals on how to create a human being, how to maintain that human being, how to regulate that human being.
And if you'll remember the analogy that we used, it was like comparing DNA to how to build an airplane. If you have all these manuals sitting around in a hangar on how to build an airplane, it's kind of similar to that concept. It's not just building an airplane from parts that are already lying around, but having to go create those parts when we need them, how to mine them out of the earth, how to form and shape the metal.
And where we left off in our previous session was that when we make changes to that manual- now, again, if evolution is true, the manual has to change or you'll only ever get what the manual wants you to create- so when we change this manual by accident, it tends to degrade living things. Things tend to go downhill. So that's kind of where we left off.
In this session- and again, the title is Evolution's Extinction Engine, because when we change the manual, when we make changes to this delicate, intricate manual, it tends to take things down in the wrong direction. Today we'll take a little bit deeper dive into DNA. And we'll look at some very fascinating, intricate things inside that just blows the mind when you think about how a blind three-year-old, in my example, totally based on random chance, could create these wonderful things that we see in nature.
4-Dimensional Genome
We'll look at four dimensions of the genome today. There are actually more dimensions that we could talk about, but I'll pick four because that's a nice number to begin with. And what I want to do is start with the genetic alphabet.
If you've ever heard of that term, genetic alphabet, here's what it's referring to, these four letters: A, T, G and C. Now I don't want to leave you with the impression that when we look inside the cell and we look at DNA, we see these letters. We don't see these letters at all. We see four chemicals, and these are the letters that correspond to those chemicals. When I'm teaching students, I sometimes come up with an easy way to remember things. An easy way to remember these letters is to put this with them: ATGC, Advanced Technology God's Creation, A, T, G and C. That's the way I remember it. You can have your own way if you like, but where we get these A, T, G and C is actually from chemicals.
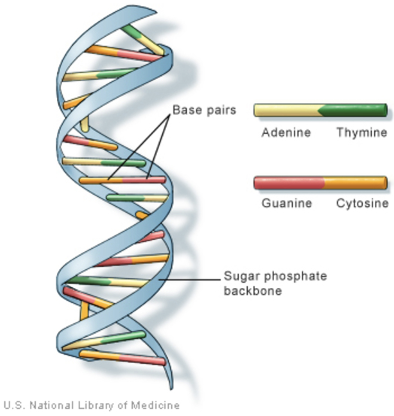
You can see the four chemicals in the above image. A is for Adenine, T is for Thymine, G is for Guanine, C is for Cytosine. So when we look at DNA, we see these four chemicals repeated over and over in various patterns all throughout the genetic code.
And how big is this code? Well, if you think of it like the ladder that is shown, you have two sides of that ladder and you have rungs up and down the ladder. If you split that ladder in half and take it apart or unzip it, if you will, then you'll get an idea of what we're talking about on this code. The code is read by looking at half of the ladder, the other half of the ladder is not read. And this ladder contains about 3.2 billion rungs, half of it. So if you look at the entire genomic code, it's actually going to be 6.4 billion letters. It's a really, really large code. We'll look at what we mean by this code here in just a moment. When we talk about the ladder and these base pairs going forward, this will make more sense when we look at the code. Just know that we're not talking about letters. We're actually talking about chemicals: Adenine, Thymine, Guanine, and Cytosine.
Human Y Chromosome: First 700 Chemicals - 1st Dimension

So the first dimension that I want to look at, what we're looking at here, is the first 700 letters, or 700 chemicals of the human Y chromosome. The Y chromosome is found in males, we talked about that in an earlier lesson. And the way that these chemicals are read is three at a time. So I have the first three letters highlighted, C, T and A. Remember, we don't see the letters, but we see the chemicals: Cytosine, Thymine and Adenine. These are the first three chemicals of the genetic code of the Y chromosome. And the way that we want to think about all these letters that are jumbled together is more like a chapter in a recipe book. And inside of this chapter we have recipes for different kinds of things that we need to make. And in the genetic code, it's no different. So out of all of these letters in the Y chromosome, the first 700, there's a section of these that are going to be for a specific type of recipe.
In other words, the long list of letters that are highlighted in the above image tell the cell how to build a specific part. Now, in a previous lesson, we looked at the bacterial flagellum, the tail that spins and makes that bacterium go and move around in the cell. Let's say one of those parts of the tail was a rotor, another part was a stator. we could say that this section tells the cell how to build a part that's going to become a part of the rotor. This is the way we would look at this. Different sections in here are going to be responsible for different parts. And that's basically how it works.
Now in the human genome, there are about 22,000 of these places that code for parts, or proteins. When I say parts, I mean proteins, when I say proteins, I'll mean parts. So 22,000 places in the cell, which would lead you to believe that the human cell can create 22,000 parts. That's really not the case, we'll see coming up here in a moment. But just for now know that there are 22,000 places in the cell, in the DNA, which actually code for a specific part. And this is read linearly, so beginning from the first letter to the last letter in this section, that's going to be one part. This is exactly how computers work today, when we think of coding, right? We start with a piece of code, we read sequentially, I'm going to use it in human terms, from left to right. So we're very familiar with this. I did coding for a number of years early in my career, and I wrote code like this all the time, read sequentially. So this is the first dimension. Nothing too surprising here, I don't think, except for the fact that we have a code. We haven't really talked about that yet.
So speaking of codes, coding and decoding, when we talked about those airplane manuals, we imagined that hangar full of all of these manuals on how to do the mining, the refining and everything that we talked about before. We raised the question, "Okay, it's great, we have all these manuals. Now, what? We have an airplane, right?" Well, no, of course not. We have instructions for how to build it, but unless we have something that can understand it, it doesn't do us any good whatsoever.
In order to demonstrate that, I'm going to go to Daniel 5:25. In this verse we have this message. So, setting the context here, we have King Belshazzar, who's holding a feast for 1,000 people. One thousand people! They're probably just a few of his closest friends, maybe a few relatives, right? Now Belshazzar's father, Nebuchadnezzar, had actually robbed the gold vessels: plates, utensils and chalices and cups from Jerusalem. They stole them. They took them from Jerusalem. And Belshazzar thought this would be a great time to break out those golden vessels, during this feast with 1,000 people.
And that's what he did. They got the golden vessels, they began to eat. And while they were having their feast, a hand emerged with fingers that resembled a human hand and began to write on the wall. Now, where did that hand come from? Another dimension, perhaps? Maybe that's a future lesson that we can talk about when we discuss dimensions. But you can imagine, this kind of startled Belshazzar, probably all of his guests as well. And this is what was written on the wall:
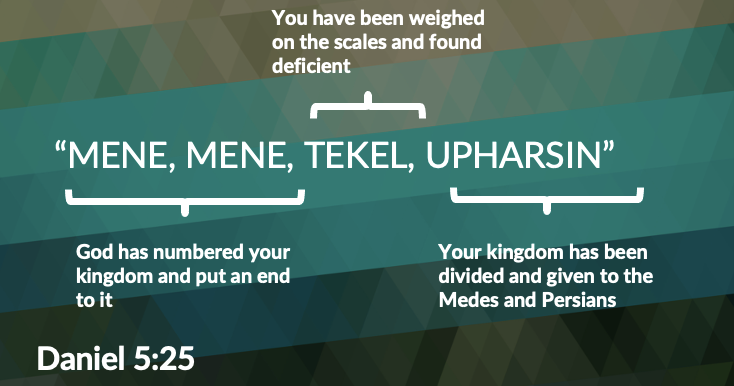
Now, this meant absolutely nothing to the king. In fact, it didn't mean anything to anybody at the banquet.
The king called in his cabinet, his trusted advisors, his wise men, and they didn't know what it meant. So the first thing we need to remember about a code or language is if you're the only one that knows how to decode it, it is absolutely useless. It doesn't do anybody any good. In fact, I remember in high school one of my best friends and I created our own secret language, so that we could write things in class and pass them back and forth, and no one would know what we were talking about. We could talk about the teacher, we could talk about other students. And it was just good fun, right? Well, it was fun until our computer teacher discovered the note and being as smart as he was, he deciphered our language and then he understood it.
But the idea here is that my friend and I, we agreed upon this language, this syntax, so that we could understand what the language was. And if God was going to convey a message using a coded language, there has to be someone that can decode it. Well, there was in this case, it was Daniel. Daniel decoded the message. And he delivered this message to the king: that God has numbered his days, he had been weighed and measured and found deficient, and his kingdom was going to be taken over by the Medes and the Persians.
And that's what this code meant when it was decoded. Now, DNA is the same way. If you have this code and you don't have something that can understand it or decode it, it does you absolutely no good. And in our cell, this is where those enzymes, those workers come in. They can read the cell, they can unzip the DNA, they read the three letters at a time, and they know what these letters mean and how to decode them.
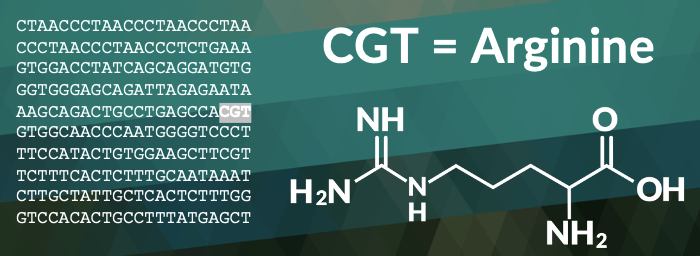
In the above example I've highlighted three letters, C, G and T. In the decoding language of the cell, CGT means Arginine. That's one of the 20 essential amino acids that makes up and is required by living things.
Just below that I've included the chemical makeup. You can see it's got hydrogen, nitrogen and oxygen and how those bond together. there. An amazing thing we need to look at with this code is: who told the cell to read these chemicals three letters at a time? Now, in retrospect, we can think hindsight-wise, well, it must be in three if we're going to have 20 amino acids and we can work out the math, but that's hindsight.
How did these cells, how did these enzymes know, initially when I'm unzipping the DNA, to read them three at a time? It's called a codon. Who told these enzymes to do that? You need two people at least at a minimum or two entities involved that know the code if you're going to have communication, and in this case in DNA, we have DNA and we have enzymes, and those are our two entities there.
Alternative Splicing - 2nd Dimension
Looking at the second dimension, something very interesting happened. After the Human Genome Project, when the genome was decoded, or we thought we had decoded everything there was to know about DNA- we were just actually scratching the surface- remember we said there were 22,000 places, and we'll call them genes, they're instructions on how to build a part. Well, the problem is the human body can make more than 500,000 distinct parts or proteins. We only have 22,000 places where we have instructions for a part. How can the body do this? How can the cell do this? This is absolutely amazing.
We have 22,000 instructions to make a part, yet we have 500,000 parts. How does that happen? Okay, let's take a look at this. Below is a section of the genetic code, beginning with A and ending with T.

In reality, these genes, these instructions, are much larger than this. On average, there are about 27,000-28,000 letters. Some get much, much larger. So how does the body do this? Well, it does this by something called splicing, which we'll look at here in a moment. But for now know that when the cell takes an instruction set like this one, there's going to be pieces of it or chunks of it that aren't involved in the instruction process. The cell doesn't need them to build that part.
So when a cell needs to build a stator, for example, for a bacterial flagellum, it'll take the instruction set here, and it knows these black and white pieces- I colored them black and white just for illustration purposes- the cell knows not to use those. So what it ends up with is that it uses the color pieces, the yellow, and the purple and the green, and it pushes them together. That's the instruction set.
To further illustrate this I have a section of DNA here with some color-coded tape (see video 14:43). The color-coded tape is going to represent the pieces of instructions that the cell needs. And then the darker color on the rope is the parts that aren't needed. So when this gene is read, you can see there's a lot that's not needed. In fact, this is how it is in our DNA. The part that's needed we call exons and the part that's not needed we call introns. But essentially what we want to end up with are these colors together making our recipe, making our instructions, making everything look correct. And then these parts that are below and looped, they're snipped out, they're cut out so that we wind up with only the pieces that we need.
Now, this is absolutely fascinating that these enzymes can go to this section of code, take out this section of code and know which pieces to snip out in order to get the final recipe. It's called splicing. You may be asking, well, how does this worker in the cell know how to do this? We're not going to get into all that complexity, but just know that inside of here, there are actually markers: beginning markers, ending markers.
I want you to keep this in mind as we're talking about this. Evolution is that blind three-year-old, right? Has no brain, has no intelligence, has no forward thinking, doesn't keep a scientific notebook; everything's just happy, random chance and coincidence and accident. It's mind-boggling to think that accidents can create a language or a code, because that never happens. That's not our experience, that's not evidential.
If you take this a step further to say not only can it do that, but there's a code within a code. There are stop markers, there are start markers in here. There are places that tell the enzyme where to snip, what places to cut out. How does that happen by chance? How does that happen without a mind? This has all the hallmarks of design, if you can open your eyes to see it.
But the magic doesn't end there. Remember, we have 22,000 places that code for parts, but we can make 500,000 parts. Now, this is where it gets even more interesting. What the cell can do is take these parts that it keeps, the exons, and it can rearrange them and make different parts out of the same code. If you notice, in the above image, the same code (designated by color) has been rearranged from line to line. I put the colors in here so we can kind of see that I'm changing things around. Instead of it being green, purple, yellow, now it's green, yellow, purple. Or I could just use two of them, yellow and purple or purple and green.
So you can see how the cell can do this mix and match. This is how we take 22,000 instructions and we get 500,000 different parts out of them. This is absolutely genius, because it's efficient, right? We're having the smallest amount of code in a small amount of space and being able to rearrange it and get all these different parts. Well, why not just include all of these instructions piece by piece in the genome? You'll see that here in a moment. The genome is quite large and it has to go in a very, very tiny place in the cell.
How do you maximize efficiency? Well, this is one way. You're using the least amount of parts and getting the most amount of results out of it. Accident? Chance? Man, we sure are lucky to be here, aren't we? And I say that tongue in cheek. There's a mind behind this, there's intelligence behind it. And so each one of these combinations will produce a different part or a different protein. That's alternative genetic splicing and our cells know how to do this. Those enzymes, those workers in the cell, they know how to do this. They know how to read and decode the language. They also know how to read the start signs and the stop signs, and they do it very well. However, we live in a fallen world- you can always kind of trace back to Genesis in one way or another. And remember in Genesis chapter three, when sin was introduced into the world, that there was punishment.
Remember we talked about thorns as being a part of that punishment. And I talked about Colossians 1 where it says, "In Him, all things hold together." Maybe God just held back a little bit of His holding power, and what we see now is we see things that are not exactly perfect. God's once perfect creation is now no longer perfect. So there are imperfections in this process. They're called splicing errors. Now, initially, when this was discovered, those who held to the evolutionary ideology would say, "Well, this is how evolution had a playground to kind of work and test things." However, the more knowledge that we gained, the more we found out this really can't be true because when things go wrong in this splicing, that produces diseases. Something like cystic fibrosis is a splicing error.
What do I mean by splicing error? Well, let's say that the splice doesn't end at this G here in the green, but it goes over into the dark. And so it's got more code than it should have to build a part. Well, it's not going to build the right part now, is it? Because it's spliced in the wrong area. Spinal muscular atrophy, muscular dystrophy, are other splicing errors. There's one way that muscular dystrophy happens, that's due to splicing errors. Now speaking of muscular dystrophy, there's one gene, one instruction set that codes for a part and this part's called dystrophin, it's a protein. It's a really, really long instruction set in the body. In fact, it's about 2.5 million genetic letters. It's huge, it's humongous. How many of those letters get used and how much gets spliced out? 2.2 out of that 2.5 million actually get removed, so you're left with about 300,000. And you might be asking, "Well, what do these black and white places do? Why are they in there?" Well, initially evolutionists thought this was junk. This is leftover from the evolutionary process because when we look at the entire genome, only 2% is actually coded for parts. What was the other 98% for? Well, it must be junk.
Now here's where your worldview affects your science. If that's junk, why would I look at it? Why would I bother applying science to that part? But if your worldview is based on the Bible where God doesn't make junk, things were perfect at the beginning and decayed and went down over time. Well, I might want to find out what uses are in those introns, those places that don't code for parts. So it turns out they're very important. Now we know that nearly the entire genome, including those places that don't make parts, are essential things for regulatory processes.
So this is the second dimension of the genome. This alternative splicing basically gives us a code within a code. Think about that for a moment. We have our 22,000 codes, but within those codes, there are codes that live inside of them. And the body knows how to bring these about. We don't program this way. This is not a way we typically program. So going back to this idea of why the efficiency in alternative splicing? Why do we need this? Why not just put all the instructions in there and have each one laid out sequentially? Well, let me lay out the problem. The problem is that we take one of our cells, just one of our cells, and we have trillions, we take the DNA out and we put it end to end. In one cell, that DNA is going to be about six and a half feet tall or about two meters. That's a lot. That's a lot of material to cram down into a microscopic cell. Not just the cell, but the nucleus of the cell, which is about 10 micrometers wide. That's really, really small.

To give us a little better example, if we take the cell nucleus where this DNA lives, and let's just make it the size of a soccer ball. If it's the size of a soccer ball, that means we need 50 miles of DNA to be crammed inside of this space. This is why it's important that DNA folds properly. This is why it's important that it be able to be unzipped easily and quickly when we need to read the code. This is why we have alternative splicing to make best possible use of this small space. Oh, and just something else to consider, the 22,000 genes that we have, worms also have 22,000 genes, so you can draw your own conclusions there. That was one of the big questions when we found out that we have the same amount of genes as worms and jellyfish, yet we are much more sophisticated. Well, alternative splicing goes a long way in that regard, doesn't it?
Folded DNA - 3rd Dimension
Okay, so talking about another dimension here, still thinking about this three-dimensional space. When you're creating a part, you may need to follow different kinds of instruction sets to create the whole part. For example, that motor on the bacterial flagellum that whips that tail around, you've got the rotors, you've got the stators.
So you're going to have instructions that, for efficiency, need to be close to each other. Remember the genome, 3.2 billion letters long. It makes no sense to have instructions for the base part of that tail to be spread out across the entire genome. For efficiency, they need to be close together. Yet what we find is when we spread the DNA out, sometimes these instructions are not close together at all. They're far apart. But we're not thinking third dimensionally. Take these two instruction sets here, that are highlighted in the image below, let's say that they're used together often, that if one is used, almost always that the second one is used.

Well, when the DNA is folded in the cell, then they become closer together in the three-dimensional space. Accidental, blind three-year-old? I don't think so. This is next level storage, right? When we can take these genetic loops inside the cell, inside the nucleus and have this type of proximity for the genes that we need, that we often use, this is making the best possible use of that tiny space.
So this is the third dimension of DNA that I wanted to point out. It is pretty incredible. We don't program like this either. We don't know how.
Imagine taking a book, your favorite book and then folding it in half, and then being able to read top down through the book and have it make sense with the words and everything. We don't even know how to program like that, right? Sure, there's palindromes, and we can do things like that, but we don't program like this because computers can't decode like this. They don't know how to do it. Even if we know how to do it, conceptually, we can't get a computer to do it. And looking at this complexity, with the compactness and the folding and the alternative splicing, this molecular biologist said this:
It was just like seeing another planet, this whole new world. You get lost in it.
- Clodagh O'Shea
Molecular Biologist
Salk Institute, La Jolla, CA
PNAS, October 13, 2020
117(41)25186-25189
I want to take just a second and remind us of the difference in something that man makes and what God makes. I don't believe nature did this by accident. This is the product of a mind. You take something, I think I've used this example before, you take something like a razor blade. When you hold it up, it looks exquisitely sharp and fine. If you put it under a microscope and you blow it up 3000 magnification, what do you see? It's not a straight line, is it? It's jagged. In fact, it looks terrible. Like, wow, I'm putting that on my face? But when you magnify something that God has made and you go deeper and deeper into it, the more your jaw drops. You don't see imperfection. You see more and more complexity.
You can imagine Darwin, back in his day, looking under a microscope that he had, looking at a cell, seeing the nucleus, not knowing what was inside of it, but kind of seeing lumps inside. Like, ugh, it's kind of a lumpy, gelatinous material. He had no idea. And then over the last 100-150 years, we've been able to develop technology to take us deeper and deeper. And what looked unimpressive initially, really is a whole other world, as this molecular biologist has said.
And what's even more amazing to me is that this is discoverable. God didn't make things that were so complex that we could not discover them and understand the processes. There are some things, well, a lot of things, we still don't understand, but as time goes on we can understand more and more.
Time - 4th Dimension
Now let's talk about the fourth dimension that I want to look at today.
So remember, we have the sequential dimension, where we read one letter at a time in the genetic alphabet. We have the alternative splicing, where we can mix and match one instruction set to get different parts. And then we have this concept of folding. And I've only talked about folding in one aspect, and that is inside of that nucleus, you can imagine all this stringy DNA everywhere. Some of it is kind of like wadded up into tight parts, another is kind of loosely packed because different cells need different instruction sets. For example, a cardioblast cell in my heart, it needs different kinds of instructions than a liver cell that's working on metabolism. They don't do the same things. They'll need some of the same instruction sets, sure.
Now here's part of the fourth dimension that we don't understand: Different cells need different types of instructions from the same set of DNA, and that instruction set can change over time.
Time is the fourth dimension. This is something that was just recently discovered in the last couple of years. Well, at least it was more fully known in the last couple of years, and I'll give you an example.
Let's go to the liver. So we talked about our cells. In the nucleus we have 23 chromosomes, 23 pairs of chromosomes, but in the liver, some cells have more than that. Well, now wait a minute. When we were talking about chromosomes, I said if you have an extra chromosome, that's generally bad news. That's tied to a disease, right? And it's not good. Well, that's true when that's throughout your whole body. But in your liver, it needs certain sets of instructions and it needs to get through them very quickly and create these parts very quickly, such as in metabolism or detoxification. And in order to do that, it actually makes copies of what it needs.
Rather than God saying, "Hey, I'm going to put these extra copies in every cell all throughout the body and make that tight space even more crowded," no, the liver just says, "Hey, I need these sets of instructions, and I need mass production. I need multiple workers making multiple parts out of these at the same time, so I'm going to make copies of it." That's how it can change over time.
In our brains, we have this concept of jumping genes. Whenever I say jumping genes, it reminds me of a childhood video I used to show my kids teaching them the letter J. You know, "Jumping Jane"? If you don't know about it, that's okay. But these jumping genes are also called transposons, meaning that these genes can move places throughout the genome in certain brain cells.
Now, initially, when this was discovered, again, with the evolutionary mindset, they were tempted to say- Well, they weren't tempted to say, they said, "Oh, this is left over from an evolutionary ancient virus." Well, it turns out that's not the case at all, that these transposons, these jumping genes, are absolutely vital to brain development. We wouldn't have the kind of brain we have without them. Now, in case you didn't catch that, this is very subtle. The DNA, the genome, can reprogram itself dynamically over time. You go way beyond chance and probability when we're talking about a code that can dynamically reprogram itself without messing itself up.
Computer scientists dream of this, to be able to develop code that can dynamically change itself over time without destroying itself or running out of control. We don't know how to do this. Computers don't even know how to read this if we could figure out how to do it.
But this is the fourth dimension that I'll want to end on today. And that is: This whole thing can change itself as it needs to over time; not in a macro evolutionary kind of way, but in a maintaining growth and development kind of way. It's very controlled.
So there are the four dimensions of the genome. And again, hopefully as we went through this, you kind of thought to yourself, "How would a blind, unintelligent, random process do this over time? This is not the process of chance. This is the process of intelligent design." And we can see this right here in our cells.
I'm not the only one who thinks this. There are evolutionary scientists who believe the same thing, that this must be the product of a mind.
And here I want to talk about Francis Crick. If you recognize the name, Dr. Crick is one of the co-founders of the structure of DNA. He won a Nobel Prize in 1962 along with his colleague- Watson and Crick, if you've kind of heard the pair taught together.
And so, to overcome this hurdle, once he discovered the code structure and they began to learn more and more about DNA and the code, he knew this could not be the product of chance. Codes don't create themselves. I don't care what the medium is, whether it's nature, it doesn't matter. Codes don't create themselves. So he wrote a book called "Life Itself", and he proposed an alternative theory. Not a God theory. That is an alternative theory. What did he say? What did he propose? You ready for this? He said, "that some form of primordial life was shipped to earth in spaceships billions of years ago by some more evolved civilization." Because hey, if there are aliens out there, they must be more intelligent than we are, right? And that's how life got started on earth- is that some mind created the code. They kind of kickstarted the process and then shipped it to earth and then chance and eons of time took over from there.
Two comments on that just real quick. One, really? Alien civilization? A Nobel Prize winner writes a book and he's serious about this alternative, which, is not really funny. It's true. He's absolutely correct that there's no way the genome could have written itself. It doesn't matter how much- you could have an eternity worth of time and it'll never happen. Just like that hangar full of airplane manuals. I asked the question, "How long would it take for these manuals to write themselves?" No one ever says, "Well, so it's two minus eight... 10 billion years." No one ever comes up with a number because they know it's impossible. You can't do it. It's the same thing here.
Now, by saying that there's aliens out there that did it, that's just kicking the can down the road, because that begs the question: Where did the aliens come from? How did they evolve? Presumably they've got the same type of information inside of them. That's not an answer at all, right? And in fact, Michael Denton, a molecular biologist says,
Nothing illustrates clearly just how intractable a problem the origin of life has become than the fact that world authorities can seriously toy with the idea of panspermia.
- Michael Denton, Ph. D.
Molecular Biologist
"Evolution, a Theory in Crisis"
And this is what Francis Crick called his idea, panspermia. Pan meaning everywhere, all around, like DNA is all around; and spermia meaning seed. So life was seeded from spaceships from somewhere all around.
Now we could get into some side conversations at this point. Sometimes when I'm talking with an atheist that's may be a scientist who's a physicist or a biologist, and they say, "Well, yeah, we've found biomolecules on meteorites that have landed on earth." That's great, you found biomolecules. That is a far, far cry from even what we call a simple cell. How do you get from a biomolecule to a cell with all of the intricate things inside of it, the DNA, the code? You can't get there.
And by the way, when they find these biomolecules, they're called racemic, meaning that there's left-handed molecules and right-handed molecules, and when you have that in life, they don't work. You need one hand or the other. It's a problem. But at any rate, we're not going to go down that sidetrack very much further than I already did. When you put all this together, and I firmly believe this, there's a revolution happening in science where we're kind of coming back to this.
When you look at the science, and when you look deeper and deeper in the cell and the goalposts of evolutionary ideology you just keep getting moved further and further out. I believe science does not lead to a disbelief in God, not at all, just the opposite. I believe that when you do science, that it moves you to a disbelief in atheism, because you just can't get there. You can't get from point A to point B using the evolutionary engine that we keep talking about.
So going back to our anchor verse, and we'll kind of wrap this session up, Psalms 139:14.
I will give thanks to You, for I am fearfully and wonderfully made;
- Psalms 139:14
Wonderful are Your works,
And my soul knows it very well.
We've looked at different parts of this verse in previous sessions. And today I want to focus on that middle piece. Wonderful are your works. When we look at alternative splicing, when we look at a genetic code that can reprogram itself over time, we have to give credit to something, to someone. And I believe in giving honor where honor is due. That's a biblical concept. And in this case, we give credit all to our Creator, all to the Intelligent Mind who has no limits or no bounds when it comes to thinking and knowledge.
So that's going to wrap it up for our four dimensions today. In the next session we'll go a little bit deeper into some of the molecular machines while we're looking at energy and how energy is made in the cell.
Thank you for your attention and look forward to our next session.
